Telling markup from text
I have a simple problem: I need to pass a piece of text, a title, through Atom aggregators so their users see it correctly. That piece of text is The <form> and the <button> should not be interpreted.
It would be easy to misunderstand what Atom (RFC 4287, w00t!) is all about: since the community-backed and open-standardized parts of it took years, you might think that’s what it’s all about. It’s not. It’s about two things: relative URLs, and absolute certainty about who is a moron when something involving the less-than character doesn’t display correctly. Go back to the start, when Sam first began talking about it. Relative URLs and a clear content model.
Atom text constructs, including atom:title, can have a type attribute, with one of three values: text, html, or xhtml. If there’s no type attribute, the default is text. That tells you what’s coming out of your XML parser.
With either <title>The <form> and the <button> should not be interpreted</title> or <title type="text">The <form> and the <button> should not be interpreted</title>, which are the exact same thing, your parser will hand you The <form> and the <button> should not be interpreted along with the knowledge that it is text. For browser-based aggregators, if you need to display text in a browser, you replace & with & and < with < and bung it in (or, you do a bunch of fiddling with JavaScript, possibly needing to escape quotes along the way, but if the end result isn’t the same, you’ve gotten it wrong).
With <title type="html">The &lt;form> and the &lt;button> should not be interpreted</title>, your XML parser will hand you The <form> and the <button> should not be interpreted along with the knowledge that it is HTML. That’s what you put in the browser, so bung it in directly.
With <title type="xhtml">… well, things get complicated depending on your parser’s API, and I’m willing to cut you some slack if you screw up. Too bad for the people that feel they have to use it.
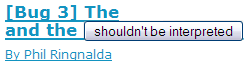
So, what do you give me? With type="text", Bloglines fails to escape the text before trying to display it as HTML, so the title has the start of a form, and an actual button labelled “shouldn’t be interpreted”. Google Reader, My Yahoo!, Gregarius and NewsGator Online decide that the example tags are actual tags that they don’t like, and strip them, displaying The and shouldn’t be interpreted. In all five cases, those are bugs in the aggregators, and that’s the point of Atom: there’s no question, no wiggle room: if you treat text as markup, whether by letting it be interpreted by a browser or by removing it as unsafe markup, you have a bug.
With type="html", Bloglines, My Yahoo!, Gregarius and NewsGator get it right: apparently they simply treat all titles as HTML, so they correctly handle an Atom title in escaped HTML. Google Reader decides that the example tags are actual tags that it doesn’t like, and strips them.
On a (not so-) wild hunch (since it’s the source of the XSS vulnerability I reported to them a month ago), I gave Google Reader a type="html" title with the less-than characters double-escaped, as &amp;lt;form>, at which point it correctly displays the title. The bug I discovered was that they were double-decoding and then interpreting the results; they apparently fixed it not by only single-decoding, but by double-decoding and then stripping things they don’t like.
Displaying text from an XML feed in a browser is a four-step process, and you don’t get to skip any steps, and you can’t do them out of order:
- Parse the XML.
- Put the character data in a deterministic state.
- Sanitize the data.
- Prepare the data for your particular display needs.
If you don’t have the parsing down, you’re not even in the game.
The very next thing you need to do with the characters your parser handed you is to decide what they were, and put them all in the same state. Because there’s no way to tell the difference between “a less-than I intended to display as a less-than” and “a less-than I intended as the start of markup” in plain text, that state needs to be HTML, whether or not you are going to allow HTML markup, or even whether or not you actually have an HTML renderer.
With RSS titles, it’s pretty much up to you what they were supposed to be: there has never been a spec which says that the content of the title element is escaped HTML, one spec explicitly said no HTML markup, but if you look at actual examples, whether it’s things that look like markup or things that look like named entities, you’ll find that most people are treating it as escaped HTML, wanting &copy; to display © rather than ©. Write a heuristic to guess, be an asshole and treat them all as text, bow to the inevitable and treat them all as escaped HTML, I really don’t care: this is exactly why I will no longer produce RSS. Just don’t get distracted thinking about whether or not you want to display HTML in your titles: that comes later, right now you aren’t doing anything other than determining what state of escaping the original is probably in, and if you believe that state to be plain text, converting & and < to & and <.
With Atom, it’s simple, and that’s the whole point of this ramble: if there’s a type="html" attribute on the element, then it is HTML when it comes out of the parser, if there’s a type="text" attribute or no type attribute it is plain text. Convert the text, leave the HTML alone, just don’t treat them as the same thing.
Once you’ve gotten everything into the same deterministic state, then and only then can you remove the things you don’t want to include, because now you know that any < is the start of markup, and any < is not. Filter out markup, remove XSS attacks, convert named entities to characters or NCRs, whatever you want, but except for things you’ve intentionally removed, your final display should be exactly the same as it would be if you just took the string at that point and put it in a browser.
And now-and-only-now, once you have $item->sanitized_title_in_html, you can do whatever sort of odd character substitution and massaging and escaping or plain-textification you need to do to make it work with your display.
So, could you, as a special favor to me, get it right, especially with type="text"? See, I’ve got these 300,000 <entry>s headed your way, many of them with a < that doesn’t signal the start of markup.
Did they just fix this or so? I don’t get it in Bloglines anymore… Good to know that Atom finally has a number by the way. Yay!